





¿Qué es un rastreador web y porqué es tan importante?
Hubo una época (y no hace mucho de ello), en la que se creaban redes para comunicar diferentes instituciones. Redes como la que unió las universidades de Stanford y UCLA en 1989 y que recibió el nombre de Arpanet.
Estas redes tenían una diferencia sustancial con respecto a las de hoy día: Todavía no habían integrado la tecnología vital que convertiría a esas redes en Internet. Una tecnología llamada hipertexto, que no era otra cosa que la incorporación a esas protopáginas de hipervínculos (links).
La posibilidad de enlazar unos contenidos con otros, pudiendo así organizar la información de manera que fuese accesible, no sólo permitió dar el paso de Arpanet a Internet, sino que en 1998, nació una empresa que comenzó a analizar y organizar realmente bien esos enlaces, haciendo accesible gran parte del contenido existente en la red. Hoy, 20 años después, esa compañía es la 2da más grande del mundo: Google (Alphabet).
Estos dos hechos históricos entorno a la importancia de los hipervínculos, nos sirven para introducir el tema de hoy: ¿Cómo es posible que no sólo aparezca mi web en los buscadores, sino que cualquier modificación que realice aparecerá reflejada en muy poco tiempo?
Siento deciros que la respuesta a la pregunta de la introducción no es «Tienen un ejército de Umpa Lumpas», pero casi.
Su ejército es de bots, es decir, pequeñas rutinas de código que funcionan de manera autónoma y cuyo objetivo es rastrear los hipervínculos que hay dentro de cada web para almacenar su contenido. Así, posteriormente, serán capaces de parsear ese contenido extrayendo la información que les interese (precios, artículos nuevos, horarios…).
Estos pequeños bots rastreadores se conocen bajo muchos nombres: Recolectores (de páginas webs), rastreadores, indexadores web, hormigas (ant), Web scutters… pero quizá, los dos nombres más populares son Crawlers y arañas web (Spiders).
¿Por qué? Porque gracias a su función de rastreo e indexación, lo que hacen en realidad es tejer una red de interconexiones que permiten mantener unidas millones de páginas webs, y por ende, su contenido.
Por eso insistimos tanto en la importancia del Internal Linking para el SEO on Page: Si no tienes enlaces a un artículo dentro de tu web, los crawlers no serán capaces de llegar a él, y por lo tanto no aparecerá nunca en Google.
Si quieres saber cómo funcionan exactamente estas arañas y cómo usarlas en tu beneficio para posicionarte mejor, ¡te invitamos a seguir leyendo el artículo!
¿Cómo funciona un crawler?
A continuación busca otros enlaces que puedan figurar en el contenido de esa web y los visita repitiendo la tarea.
Como podéis imaginar, este trabajo puede ser infinito, ya que de cada página saldrán decenas de enlaces internos y externos, y de cada una de ellas otras decenas. La estructura de enlaces de una web es una estructura de árbol: De cada rama salen otras ramas y de éstas a su vez otras más.
Dado que los recursos de un sistema siempre son finitos, serán las directrices iniciales las que marquen hasta qué punto o en qué momento un crawler ha de abandonar su misión. La lista de enlaces que haya conseguido hasta ese momento, se llamará frontera de rastreo.
Cuando finalice la tarea de rastrear y almacenar, todo ese código será parseado es decir, un algoritmo analizará el contenido siendo capaz de extraer la información que le interesa. Como decíamos, habitualmente son precios, horarios, artículos…
Con toda esa información se crea un índice accesible (se indexa) para que cuando el usuario realice una consulta, el sistema le muestre la información relacionada y sepa de dónde la extrajo.
Finalmente, cada cierto tiempo los crawlers volverán a pasar por las mismas URLs verificando que todo sigue en línea, si hay contenido nuevo, correcciones… Precisamente por ello nosotros podemos «enseñar a los buscadores» nuestra frecuencia de actualización y «concertar una cita» con ellos.
Limitaciones y problemas en el rastreo
URLs de lado de servidor
Con el desarrollo de ciertos lenguajes de programación y de determinadas prácticas SEO como la reescritura de urls amigables o el redimensionamiento de imágenes, los crawlers se encuentran ante la problemática de tener cientos de direcciones repetidas, y miles de urls inservibles.
Pongamos un ejemplo: Si en una determinada página yo inserto una galería de imágenes, el software que la genere seguramente desarrollará un sistema de urls internas asociadas a determinados anchor links. Ésto hará que la galería de imágenes muestre una versión en miniatura (thumbnail), al hacer click sobre la imagen una versión ampliada, y al usar los botones laterales se genere un «pase de diapositivas». Si además de ello puedo ordenar las imágenes según ciertos criterios, por cada imagen estoy generando 4, 5 o 5 enlaces. Todo ello son urls que, en principio, no contienen información de interés y hacen perder tiempo y recursos al servidor.
Podríamos poner otros muchos ejemplos, como urls con parámetros GET, redirecciones, versiones móviles y de escritorio con urls diferentes, etc
Por ello la programación de un crawler debe ser optimizada con sumo cuidado o podría perder mucho tiempo duplicando o triplicando información no relevante.
Tecnologías difícilmente rastreables
El recientemenre fenecido formato Flash o incluso Ajax, entre otros, supusieron retos de lectura para los crawlers en su día. En el primer caso, todo el contenido estaba en frames de películas en lugar de en HTML, y en el segundo caso, las llamadas recursivas al servidor desde el lado del cliente, alteraban dinámicamente el contenido de una web.
Con ello queremos decir que los bots leen código, y si nuestro código no cumple ciertos estándares podemos vernos seriamente perjudicados a la hora de posicionarnos en los buscadores.
Mi cuarto está desordenado: La opacidad en la Deep Web
¿Pero a mi nadie me pregunta si quiero que un spider analice mi web? Como hemos comentado, con que una url de tu página web esté referenciada en otra web que ese buscador sí tenga indexada, el crawler acabará llegando a ti.
Es como una madeja de hilo, sólo tiene que tirar de él hasta llegar al otro lado, y tarde o temprano llegará, a no ser que lo evites a conciencia.
¿Y por qué no iba a querer que mi web apareciese en Google? ¿No es ese el sueño que todos perseguimos? Es posible que tu web esté online pero sin acabar, que el contenido esté pensado únicamente para tus amigos y para ti, que sea un diario personal que nadie más debe leer, una página de pruebas, etc
Tal vez halláis oído hablar de Internet Profundo o Deep Web, y de cómo ésta web oculta no se muestra en los buscadores. Ellos, sí tienen motivos para ocultarse ya que con frecuencia en esas páginas se venden artículos prohibidos o se realizan actividades delictivas.
¿Y cómo consiguen no ser indexados? En realidad hay muchos métodos, basta con hacer todo lo contrario de lo que dicta el buen SEO:
- No des la url de tu página a través de internet. Si quieres pasarla que sea a través de plataformas privadas como chats, Whatsapp… Puedes incluso cifrar la url y/o hacer que sea terriblemente difícil de memorizar. Ejemplo: http://85.157.21.92/j39nf98ew7f3iousdf/dsfdsf833/
- Añadir parámetros a la url para acceder a la web: Los buscadores tienen serias dificultades para rastrear las urls con «?» y otros parámetros. Así que podríamos configurar el .htaccess para que la web funcionase con http://miweb.com?index=accede pero no con http://miweb.com
- Poner usuario y contraseña para acceder al contenido.
- No tener sitemap.xml y configurar robots.txt como «noindex«.
- Si es estrictamente necesario poner un enlace externo, que sea «nofollow«.
- Dado que los crawlers únicamente leen lenguaje HTML, puedes crear la web en un lenguaje difícilmente indexable.
Crawl Budget ¿Qué puedo hacer para usarlos en mi beneficio?
Como los recursos de un servidor son limitados (Sí, incluso los de Google), cada crawler pasa un tiempo determinado en una página web. A ese tiempo se le llama Crawl Budget.
A raíz de ello se ha popularizado la frase: «Si intentas posicionarlo todo, acabarás no posicionando nada«. O lo que adaptado al refranario español viene a ser «Quien mucho abarca, poco aprieta«.
Y es que si nuestra web es muy extensa y no dejo claro qué es lo más importante que deseo que aparezca en Google, puede que acabe no apareciendo.
¿Y cómo se lo dejo claro? Hay quienes recomiendan que las páginas poco relevantes estén especificadas en el robots.txt como no index, pero lo realmente importante es una buena política de Internal Linking. Te recomendamos leer nuestro artículo: Estrategias mitos y malas prácticas.
Por otro lado, actualizar siempre siguiendo unos criterios de horario, frecuencia, etc facilita mucho que los bots aprendan cuándo entrar e incluso incrementen el Crawl Budget que te asignan.
Si te interesa el tema te recomendamos los siguientes artículos:
- ¡A navegar grumetes!: Rastreo e indexación, primer contacto con Google
- ¿Cómo concertar una cita con los bots de Google?
Black SEO: Qué no hacer bajo ningún concepto
Ahora que te ha quedado claro que los crawlers leen una web de manera muy distinta a como lo hace un ser humano, quizá se te haya ocurrido que puedes poner campos ocultos plagados de palabras clave para posicionarte, o incluso servir directamente una web específica para usuarios, y cuando detectes un crawler servirle una versión optimizada para bots.
A éstas prácticas se las conoce respectivamente como Keyword Stuffing y Cloaking, y son dos técnicas de Black SEO muy penalizadas por los buscadores. Así que mejor evitarlas…
Google bot: El Crawler que lo cambió todo
Con frecuencia la gente nos pregunta qué había antes de Google, y la respuesta parece sorprenderles: «Otros Googles». Por supuesto, no se llamaban así. Tenían nombres tan diversos como Lycos, MSN, Ozú… O los todopoderosos Altavista y Yahoo.
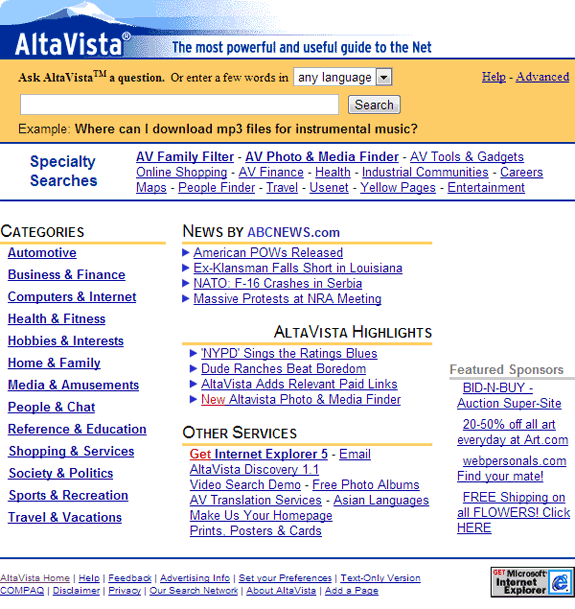
Lo que ocurre es que en los 90, los buscadores eran más como «portales web», donde además del servicio de búsqueda había interminables directorios de enlaces. La filosofía parecía inteligente: «¿Cómo vas a encontrar algo que no sabes cómo se llama?» Así que lo que hacían era ofrecerte un directorio tipo Páginas Amarillas.
¿Buscas un coche? He aquí cientos de páginas categorizadas en: Venta de coches nuevos, kilómetro cero, usados… talleres de reparación, piezas de coches, desguaces…. matriculación, ITV… accesorios, gasolineras…
Como podrás imaginar navegar por esos directorios podía ser interminable pero… Si tenían un buscador, ¿por qué no usarlo? Ahora preguntamos nosotros, ¿habéis usado alguna vez algún buscador que no sea Google o Bing? Pues he ahí la respuesta.
Los resultados eran bastante pobres, no ofrecían resultados basados en sinónimos y las búsquedas se centraban en palabras clave, de manera que si queríamos buscar un horario de trenes no había más remedio que buscar: «horario tren madrid alicante«.
Con la aparición de Ask Jeeves ésto comenzó a cambiar, y cada vez las búsquedas realizadas con lenguaje natural eran más correctas pero… Llegó Google y su «Voy a Tener Suerte», y todo cambió.
Google y su algoritmo
Google era muchísimo más rápido que sus competidores, más preciso y manejaba como nadie el lenguaje natural. Era, e incluso hoy sigue siéndolo, más cómodo preguntar a Google que levantarse a buscar cualquier cosa, incluso aunque fuese una nota personal que hubieses tomado sobre el nombre de algún local o un evento.
El buscador adecuaba sus resultados a ti, personalizándolos según tu ubicación, búsquedas previas o pautas de comportamiento.
Google tenía tan claro que era el mejor que su web siempre fue, y hoy día sigue siéndolo, una sencilla caja de búsqueda. ¿Para qué más?

Hoy en día sabemos que su algoritmo se basaba en el PageRank, una puntuación que otorgaba a cada página utilizando más de 40 criterios diferentes.
Con cada consulta buscaba en su índice la mejor concordancia posible y ordenaba los resultados según esa puntuación, que a su vez venía determinada por la popularidad entre los usuarios (tasa de rebote, nº de enlaces entrantes, volumen de visitas…). De esa manera se «aseguraba» de que lo que mostraba era de calidad.
¿Y tú, recuerdas cómo eran los buscadores de los 90? ¿Cuál utilizabas?
No olvides que también queremos que compartas con nosotros tus experiencias y primeros pinitos con los rastreadores web.



Escribir comentario